
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- terminal
- numpy
- deeplearning
- 블록체인
- pyqt
- cv2
- 브렉시트
- Inference
- Perceptron
- dtype
- Python
- 세계사
- TFRecord
- img
- TF
- error
- qtdesigner
- itksnap
- loss
- 세계대전
- 유로화
- 비트코인
- TensorFlow
- Training
- DataSet
- 퍼셉트론
- 유가 급등
- opencv
- keras
- 딥러닝
- Today
- Total
목록분류 전체보기 (118)
활연개랑
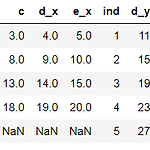 [pandas(팬더스)] DataFrame 합치기,병합 (concat, merge, join) 차이 (axis=0/ axis=1 차이)
[pandas(팬더스)] DataFrame 합치기,병합 (concat, merge, join) 차이 (axis=0/ axis=1 차이)
데이터 프레임을 합치는(병합하는) 함수로는 크게 세 가지가 있다. concat, merge, join으로 나뉘는데, 이 것들의 특징과 사용방법에 대해 알아보도록 하자. concat pd.concat()을 이용하여 Series나 DataFrame을 물리적으로 합칠 수 있다. 예를 들기위해 sr1과 sr2를 만들어보자. import pandas as pd import numpy as np col1= np.random.uniform(10,20,size=3) # 10~20 사이 실수 3개 col2= np.random.uniform(10,20, size=3) sr1= pd.Series(col1,name='col1') #col1을 시리즈로 만들기 sr2= pd.Series(col2,name='col2') #col2..
DataFrame에서 중복 행을 삭제하고싶은경우 DataFrame.drop_duplicates()를 사용한다. DataFrame이 fifa인 경우, import pandas as pd fifa.drop_duplicates() 위와같이 코드를 사용했을 경우 중복된 행중 가장 처음으로 나온 행을 제외한 나머지 행들은 삭제된다. 특정 열을 기준으로 중복 행을 삭제하고싶은 경우 , subset을 사용해준다. subset은 아래와 같이 사용할 수 있다. import pandas as pd fifa.drop_duplicates(subset=['특정 열 이름']) 이처럼 비교하고싶은 특정 열을 subset 매개변수 안에 써주고, 중복행을 삭제하는 drop_duplicates를 사용해주면 특정 열에서의 중복만을 비교할..
find_element_by_id:id 속성을 사용하여 접근 find_element(s)_by_class_name: 클래스를 사용하여 접근 find_element(s)_by_name: 속성을 사용하여 접근 find_element(s)_by_xpath: 속성을 사용하여 접근 find_element(s)_by_link_text: 앵커태그(a 태그)에 사용되는 텍스트로 접근 find_element(s)_by_partial_link_text: 앵커태그(a 태그)에 사용되는 일부 텍스트로 접근 find_element(s)_by_tag_name: 태그를 사용하여 접근 find_element(s)_by_css_selector: CSS선택자를 사용하여 접근
bs4.FeatureNotFound: Couldn't find a tree builder with the features you requested: lxml. Do you need to install a parser library? 이 에러가 나오면 !pip install lxml 을 하시면 됩니다. 그래도 안된다면 jupyternotebook을 껐다가 다시 실행하시면 됩니다~
warnings.filterwarnings('ignore') 경고 메시지를 무시하고 싶을 때: import warnings warnings.filterwarnings('ignore') 또는 import warnings warnings.filterwarnings(action='ignore') 다시 경고 메시지를 활성화하고 싶을 때: import warnings warnings.filterwarnings(action='default')
import random을 하고, 랜덤한 수를 고를 때, QQ= random.randrange(a,b)를 쓰기도 하고 QQ= random.randint(a,b)를 쓰기도 합니다. 차이점은 간단합니다. random.randint(a,b) random.randint(a,b)에서는 a가 최소, b가 최대 인 범위가 됩니다 Ex. .random.randint(1,10) 이라면 1~10까지의 숫자중에 무작위로 수를 뽑는 것이지요. random.randrange(a,b,c) random.randrange(a,b)에서는 a가 최소, b-1이 최대 인 범위가 됩니다 Ex. random.randrange(1,10) 이라면 1~9까지의 숫자중에 무작위로 수를 뽑는 것입니다. 여기서 또 하나 다른 점이 있습니다. rando..
zip(a,b) zip(a,b)에서 a와 b에는 글자나 리스트와같은 요소들이 들어가게 됩니다. 그러면 각 리스트에 들어있는 요소들이 순서대로 짝을 짓게됩니다. 예제로 설명해보겠습니다. print(list(zip([1,2,3],[4,5,6]))) print(list(zip([1,2,3],[4,5,6],[7,8,9]))) print(list(zip('abc','def'))) ==>[(1, 4), (2, 5), (3, 6)] # a와 b의 첫번째 요소끼리 묶이고, 두번째,세번째끼리 묶입니다. 인덱스로 생각합시다. ==>[(1, 4, 7), (2, 5, 8), (3, 6, 9)] # 두 개만 되는 것이 아니라, 여러개도 가능합니다. #여러개를 넣어줄 경우 각 요소의 같은 인덱스끼리 묶입니다. ==>[('a', ..